

AWS認定AIプラクティショナー(AIF-C01)で配点の大きいドメイン2「生成AIの基礎」。その土台になるのがトークン・埋め込み・Transformerといった用語です。ここがふわっとしたままだと後の応用(RAGやファインチューニング)でつまずきます。この記事で一気に地ならししましょう。全体像は シラバスマップ をどうぞ。
そもそも「基盤モデル(FM)」とは
基盤モデル(Foundation Model)とは、大量のデータで事前学習され、さまざまな用途に応用できる大規模なAIモデルのことです。文章を扱う大規模言語モデル(LLM)もその一種。基盤モデルを「土台」に、プロンプトや追加データで目的のタスクに使うのが生成AIの基本スタイルです。
トークンとチャンク:テキストを区切る単位
トークンとは、モデルがテキストを処理するときの最小の区切り単位です(単語や単語の一部)。料金や入力上限は「トークン数」で数えられます。
一方チャンクは、長い文書を検索や処理のために意味のあるかたまりに分割したもの。RAGで文書をベクトル化する前処理などで使います。

埋め込み(embeddings)とベクトル
埋め込み(embeddings)は、単語や文章を「意味の近さ」が距離になるように数値のベクトルへ変換したものです。意味が近い言葉ほどベクトル空間で近くに配置されます。検索やRAGは、この「近さ」を使って関連情報を見つけます。
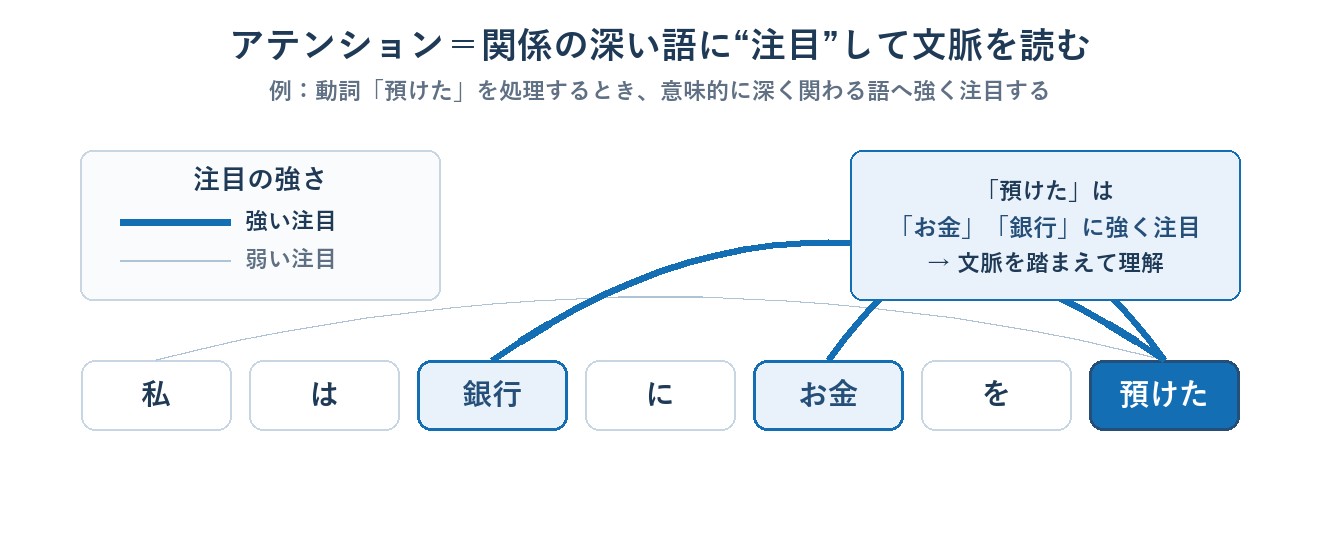
Transformer(トランスフォーマー)をやさしく
いまの生成AIの中心にあるのがTransformerという仕組みです。ポイントはアテンション(注目)=文中のどの語が重要かに「注目」して、文脈を踏まえた処理を行うこと。これにより、長い文の意味や文脈に加え、離れた位置にある語どうしの関係(長距離の依存)も効率よく捉えられます。AIF試験では仕組みの数式までは不要で、「Transformerベースの大規模言語モデル」が現在の主流と押さえればOKです。
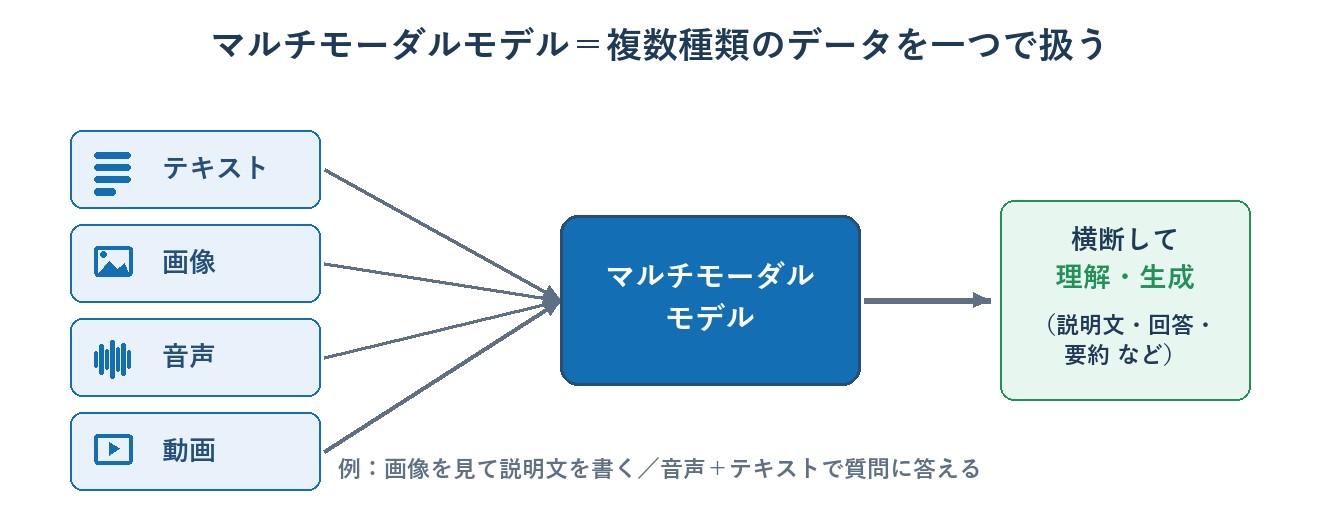
マルチモーダルと拡散モデル
マルチモーダルモデルは、テキストだけでなく画像・音声など複数種類のデータを扱えるモデルです。
拡散モデル(diffusion model)は、ノイズから徐々に画像を生成する手法で、画像生成AIの中心。テキスト生成のLLMとは別系統だと整理しておきましょう。
生成AIでできること(主なユースケース)
生成AIは幅広い業務に応用できます。AIF試験でも代表的なユースケースが問われます。
- 文章生成・要約:レポート要約、メール下書き
- 翻訳:多言語への変換
- コード生成:プログラムの下書き・補完
- チャットボット/AIアシスタント:問い合わせ対応・業務支援
- 検索・レコメンド:意味で探す検索、おすすめ提示
- 画像・音声・動画の生成:クリエイティブ制作
- トークン=処理単位/チャンク=文書の分割かたまり
- 埋め込み=意味の近さを表すベクトル(検索・RAGの基盤)
- 現主流=Transformerベースの大規模言語モデル(LLM)
- 画像生成=拡散モデル、複数データ種別=マルチモーダル
確認クイズ
Q1. 単語や文の『意味の近さ』を数値ベクトルで表し、意味が近いものを近くに配置する技術は?
Q2. 大規模言語モデルが文章を処理する際の最小単位で、料金計算の基準にもなるものは?
Q3. 現在の多くの大規模言語モデルの基盤となり、文中の離れた語どうしの関係(注意)を捉えるしくみは?
よくある質問(FAQ)
Q. 埋め込みとトークンの違いは?
A. トークンは「処理の最小単位(区切り)」、埋め込みは「意味をベクトル化したもの」。トークンに分けてからベクトル化(埋め込み)する、という関係です。
Q. AIF試験でTransformerの数式は問われますか?
A. いいえ。仕組みの詳細や数式は不要で、「現在の主流=TransformerベースのLLM」「アテンションで文脈を捉える」程度の理解で十分です。
まとめ
- 基盤モデル(FM)を土台に使うのが生成AIの基本
- トークン=処理単位、埋め込み=意味のベクトル化(検索・RAGの核)
- 主流はTransformer、画像生成は拡散モデル、複数データ種別はマルチモーダル
※本記事はAWS公式試験ガイド(AIF-C01)に基づき、エンジニアKが作成しています。


コメント