

生成AIは万能ではありません。AWS認定AIプラクティショナー(AIF-C01)のドメイン2 Task2.2では、生成AIの長所と限界、ハルシネーション、適切なモデルの選び方、そして効果を測るビジネス指標までが問われます。「どんな時に使い、どこに注意し、どう成果を測るか」を具体例つきで整理します。基礎用語が不安な方は 生成AIの基礎用語 から。
長所と限界の早見表
| 長所 | 限界・注意点 |
|---|---|
| 適応性:1つのモデルで幅広いタスク | ハルシネーション:誤情報を自信ありげに生成 |
| 応答性:すばやく回答・生成 | 解釈性の低さ:判断根拠を説明しにくい |
| 簡便性:自然言語で使える | 非決定性:同じ入力でも出力が変わりうる |
| スケール:大量生成を安定して | 不正確さ:最新・専門・社内情報は苦手 |
生成AIの長所(得意なこと)と具体例
- 適応性:再学習なしで翻訳・要約・分類・コード生成など多様な用途に対応。例:同じLLMで「議事録の要約」も「問い合わせ返信の下書き」もこなせる。
- 応答性:リアルタイムに近い速度で生成。例:チャットボットが顧客に即応答し、待ち時間を削減。
- 簡便性:プログラミング不要、自然言語の指示で使える。例:「丁寧な文体で300字に要約して」と書くだけ。
- スケール:人手では難しい量のコンテンツを安定生成。例:商品説明文を数千件まとめて下書き。
生成AIの限界・注意点と具体例
- ハルシネーション:もっともらしい誤情報を生成。例:存在しない製品仕様や架空の出典・数値を自信ありげに提示する。
- 解釈性の低さ(ブラックボックス):なぜその出力になったかを説明しにくい。例:金融・医療など説明責任が求められる場面で課題になる。
- 非決定性:同じ入力でも毎回同じ出力とは限らない。例:再現性が必要な検証・監査用途では注意が必要。
- 不正確さ:学習時点以降の出来事、社内固有・専門領域の知識は苦手。例:自社の最新の社内規程は知らない(→RAGで補う)。
ハルシネーションの原因と対策
ハルシネーション(hallucination)=もっともらしいが事実と異なる内容を生成する現象。主な原因は次の3つです。
- 知識が学習時点で固定:以降の情報や社内固有情報を持たない
- 確率的な生成:「知らない」より“それらしい続き”を選びやすい
- 学習データの偏り・誤り:元データの誤情報を引き継ぐことがある
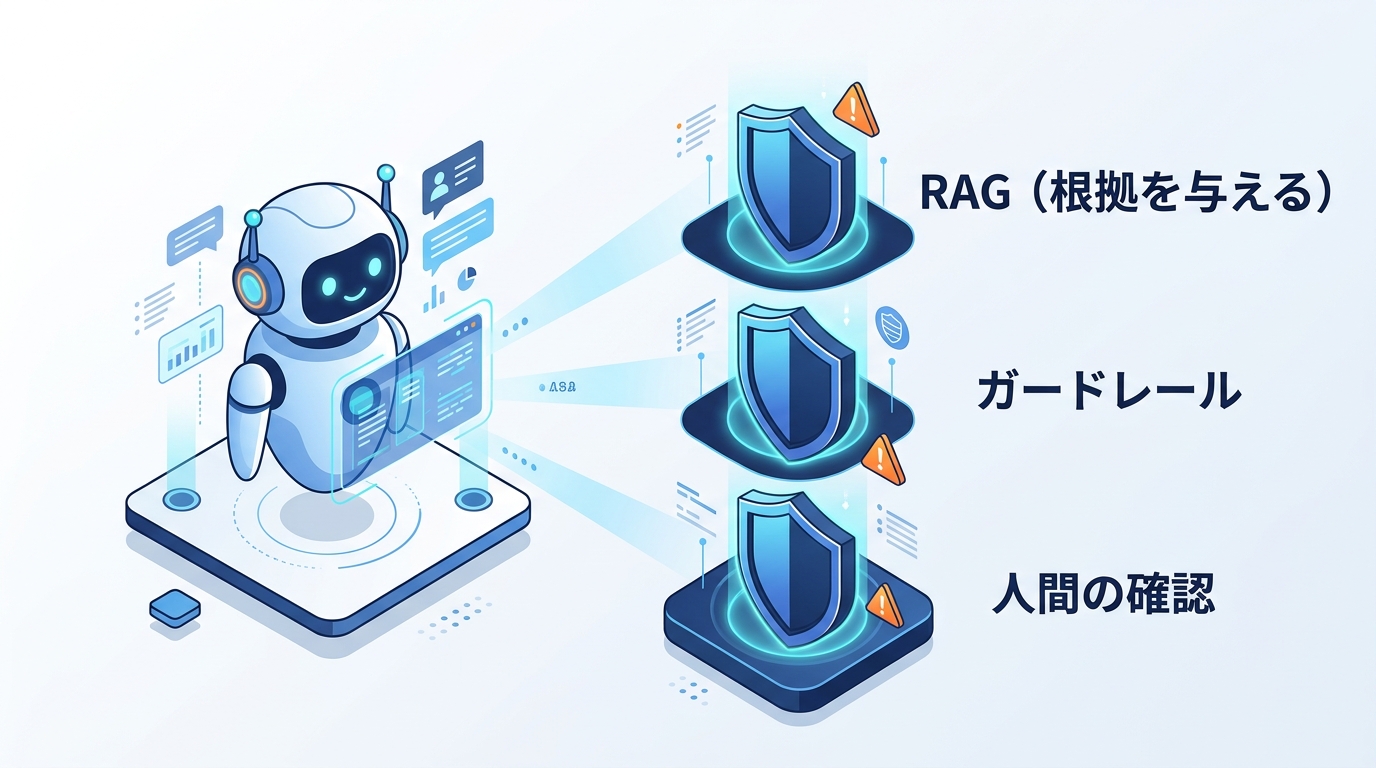
🛡 主な対策
- RAG:信頼できる文書を検索し根拠にして回答(→ 解説)
- ガードレール(Amazon Bedrock Guardrails):不適切・危険な出力を制限
- 人間の確認(Human in the loop):重要な判断は人がレビュー
- プロンプトの工夫:「分からなければ分からないと答えて」等で抑制
効果を測るビジネス指標
生成AIの導入効果は、技術指標だけでなくビジネス指標で評価します。AIF試験でも「成果をどう測るか」の観点が問われます。
| 指標 | 何を見るか |
|---|---|
| クロスドメイン性能 | 複数の業務・分野をまたいでどれだけ汎用的に効くか |
| 効率(生産性) | 作業時間・工数の削減度 |
| コンバージョン率(CVR) | 問い合わせ→成約など、行動につながった割合 |
| ARPU(ユーザー平均単価) | 1ユーザーあたりの売上への寄与 |
| 精度(accuracy) | 出力の正確さ・品質 |
| 顧客生涯価値(CLV) | 継続利用による長期的な価値 |
モデル選定で見るべき観点
- 性能要件:精度・応答速度・対応言語
- 能力:テキストのみか、画像も扱うマルチモーダルか
- 制約・コスト:トークン課金、レイテンシ、提供リージョン
- コンプライアンス:データの扱い・規制要件に合うか
📝 AIF-C01 試験のポイント
- 長所=適応性/応答性/簡便性/スケール、限界=ハルシネーション/解釈性/非決定性/不正確
- ハルシネーション対策の筆頭はRAG、出力制限はGuardrails、最後は人間の確認
- 効果はビジネス指標(効率・CVR・ARPU・CLV等)で測る
- モデル選定は性能・能力・コスト・コンプラの総合判断
確認クイズ
Q1. 生成AIが事実と異なる内容を、もっともらしく自信ありげに出力してしまう現象は?
A. ハルシネーション
B. プロンプトインジェクション
C. 過学習
D. データドリフト
Q2. 同じプロンプトでも実行ごとに出力が変わりうる、生成AIの性質を何というか?
A. 一貫性
B. 非決定性
C. 決定性
D. 冪等性
Q3. 社内FAQの自動応答で、最新の規定に基づく正確な回答を出させ、誤情報(ハルシネーション)を減らしたい。最も効果的なのは?
A. 出力に絵文字を多用させる
B. 出力をできるだけ長くする
C. 根拠となる正確な文書を参照させる(RAG)
D. temperatureを最大にする
よくある質問(FAQ)
Q. なぜ生成AIは「知らない」と言わずに誤るのですか?
A. モデルは確率的に“それらしい続き”を生成する仕組みのため、空白を埋めようとして誤情報を作ることがあります。だからRAGや人間の確認で根拠を補います。
Q. ハルシネーションはゼロにできますか?
A. 完全にゼロにはできません。RAG・ガードレール・人間のレビューで“低減・管理”するのが現実的です。
Q. 解釈性が低いと何が困りますか?
A. なぜその結論かを示せないと、金融・医療など説明責任が必要な領域で採用が難しくなります。透明性・説明可能性の確保が重要になります。
Q. 効果はどう報告すればいい?
A. 技術スペックではなく、業務効率・コンバージョン率・ARPU・CLVなど、ビジネス成果に結びつく指標で示すのが基本です。
まとめ
- 長所=適応性・応答性・簡便性・スケール/限界=ハルシネーション・解釈性の低さ・非決定性・不正確
- ハルシネーション対策はRAG→Guardrails→人間の確認の多層で
- 効果はビジネス指標(効率・CVR・ARPU・CLV等)で測る
- モデル選定は性能・能力・コスト・コンプラの総合判断
🎯 次のステップ
※本記事はAWS公式試験ガイド(AIF-C01)に基づき、エンジニアKが作成しています。


コメント