

AWS認定AIプラクティショナー(AIF-C01)のドメイン1 Task1.3では、機械学習(ML)がどんな流れで開発・運用されるかと、MLOps・評価指標が問われます。各工程の役割とAWSサービスをセットで押さえましょう。AIの基礎は AI・機械学習・ディープラーニングの違い をどうぞ。
機械学習の開発ライフサイクル(全体像)
MLの開発は、データ収集から監視まで一連の流れで進み、監視の結果を改善に反映してサイクルを回すのが特徴です。
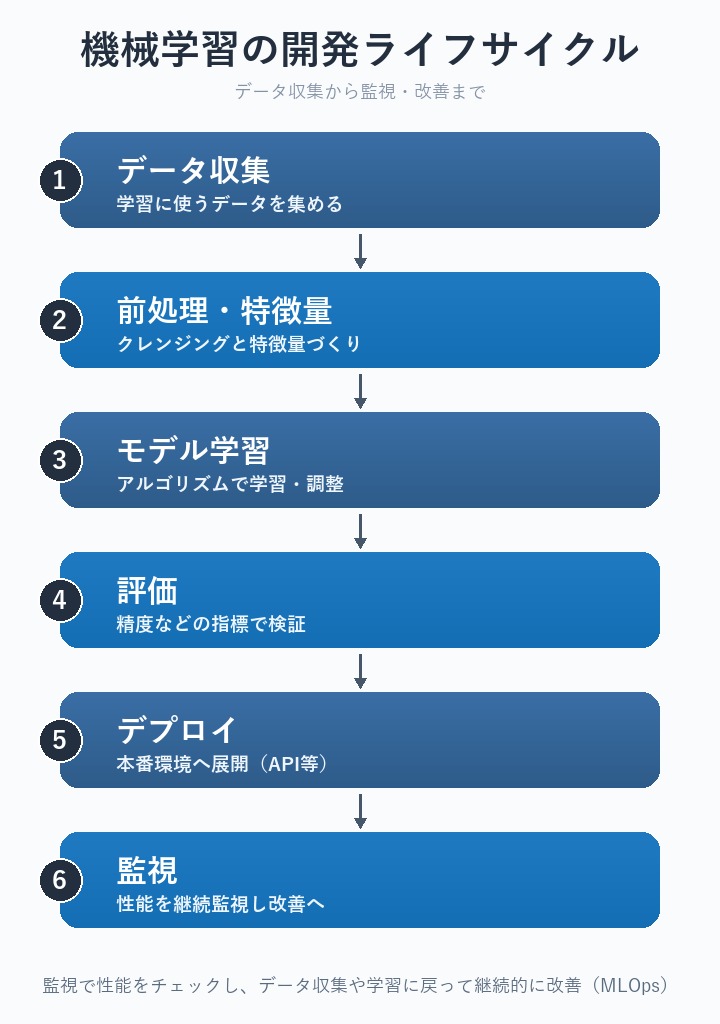
各ステップの解説
- ① データ収集:学習に使うデータを集める。質・量・代表性が性能を左右します。
- ② 前処理・特徴量エンジニアリング:欠損やノイズの除去(クレンジング)と、予測に効く特徴量づくり。AWSでは SageMaker Data Wrangler(データ準備)、SageMaker Feature Store(特徴量の管理・再利用)が使えます。
- ③ モデル学習:アルゴリズムでデータを学習。ハイパーパラメータのチューニングで精度を高めます。
- ④ 評価:指標(後述)で性能を検証。過学習(訓練データだけに過剰適合)に注意。
- ⑤ デプロイ:本番環境へ展開。マネージドAPIや自前ホスティングで提供します。
- ⑥ 監視:本番での性能を継続監視し、データドリフト(入力データの傾向変化)などを検知。AWSでは SageMaker Model Monitor。問題があれば①②③に戻って再学習します。

MLOpsとは
MLOpsは、MLの開発・運用を自動化・継続化する考え方(ML版のDevOps)です。狙いは、実験の再現性・スケーラビリティ・技術的負債の抑制・本番運用の安定。モデルを「作って終わり」ではなく、継続的に学習・デプロイ・監視して改善し続けるのがポイントです。
モデルの評価指標
評価では、技術指標とビジネス指標の両方を見ます。
- 正解率(accuracy):全体のうち正しく予測できた割合
- AUC:ROC曲線下の面積。分類性能の総合的な指標(1に近いほど良い)
- F1スコア:適合率と再現率のバランスをとった指標。偏ったデータで有用
- ビジネス指標:ROI、ユーザーあたりコスト、フィードバックなど、事業成果の観点
- 流れ=データ収集→前処理/特徴量→学習→評価→デプロイ→監視(→改善ループ)
- AWS:データ準備=Data Wrangler、特徴量=Feature Store、監視=Model Monitor
- MLOps=開発・運用を自動化/継続化し、再現性・安定運用を実現
- 評価指標=正解率/AUC/F1(+ビジネス指標)
確認クイズ
Q1. 本番にデプロイしたMLモデルが、データ傾向の変化で精度劣化していないかを継続監視するSageMakerの機能は?
Q2. 学習前のデータのクレンジングや特徴量加工を、GUI中心で行うSageMakerの機能は?
Q3. クラスが不均衡な分類問題で、適合率と再現率のバランスを見るのに適した評価指標は?
よくある質問(FAQ)
Q. MLOpsとは結局なに?
A. 機械学習の開発から運用までを自動化・継続化する仕組み・文化です。モデルを安定して学習・デプロイ・監視・改善し続けることを目指します。
Q. データドリフトとは?
A. 本番で入ってくるデータの傾向が学習時と変わってしまい、精度が落ちる現象です。監視(Model Monitor等)で検知し、再学習で対応します。
Q. 過学習(オーバーフィッティング)とは?
A. 訓練データに過剰に適合し、新しいデータでうまく予測できない状態です。評価で見抜き、データ追加や正則化などで対策します。
まとめ
- 流れ=データ収集→前処理/特徴量→学習→評価→デプロイ→監視(→改善ループ)
- AWS:Data Wrangler/Feature Store/Model Monitor
- MLOps=開発・運用の自動化/継続化、評価指標=正解率/AUC/F1
- ➡ 生成AIの基礎用語へ
- ➡ シラバスマップで全範囲を確認
- ➡ 無料模試で力試し
※本記事はAWS公式試験ガイド(AIF-C01)に基づき、エンジニアKが作成しています。


コメント